2022怎么把白条提现到自己卡里数据管理显露特效
|
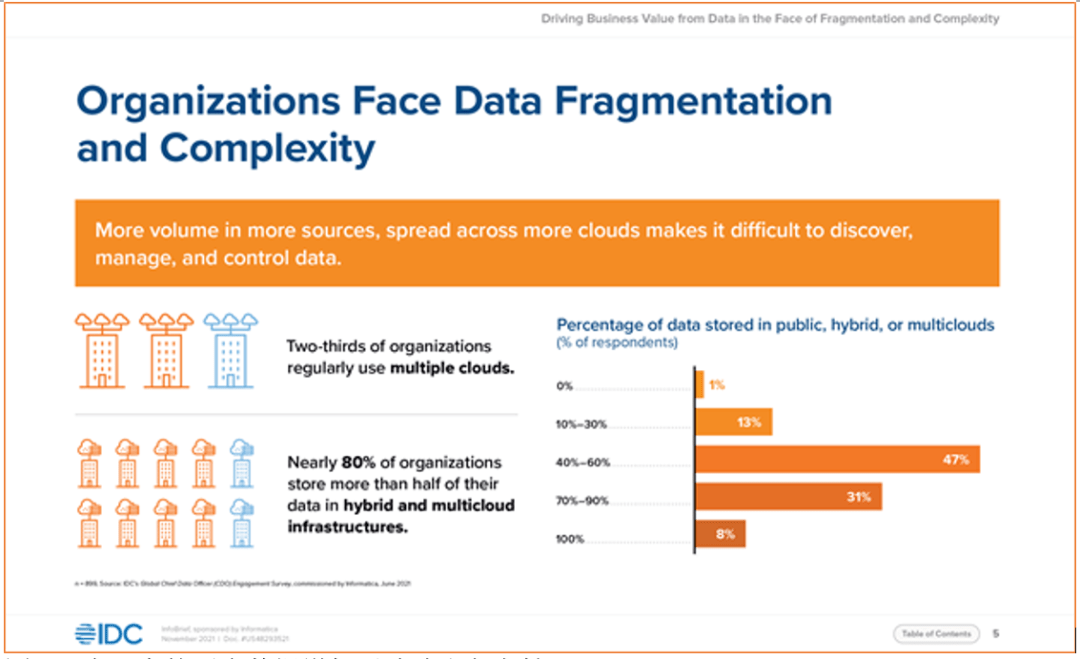
调查发现,82%的组织目前正在使用多个云,或者计划在未来12个月内使用多个云。 随着越来越多的应用程序和数据转移到云中,数据领导者面临着越来越复杂的数据管理需求:在同一个云中,跨不同的云中,以及使用本地资源。多云和跨云数据管理对于支持这些不同的拓扑结构至关重要。
多云中的更多数据增加了碎片和复杂性 多云意味着特定的数据管理服务可以在多个云生态系统上运行。例如,能够在亚马逊网络服务(AWS)、微软Azure和谷歌云平台上运行数据集成服务。无论是因为数据主权问题,还是为了避免供应商锁定或并购,多云环境的出现,企业都希望能够灵活地跨云生态系统运行其数据管理服务。 同时,云间数据管理使运行在不同云生态系统上的服务能够无缝地协同工作。例如,数据工程师可以通过运行在AWS上的数据目录和市场服务来查找数据,该服务使用运行在Azure上的数据集成服务来访问Snowflake中的数据,并将其移动到谷歌云平台,以便在TensorFlow项目中使用。
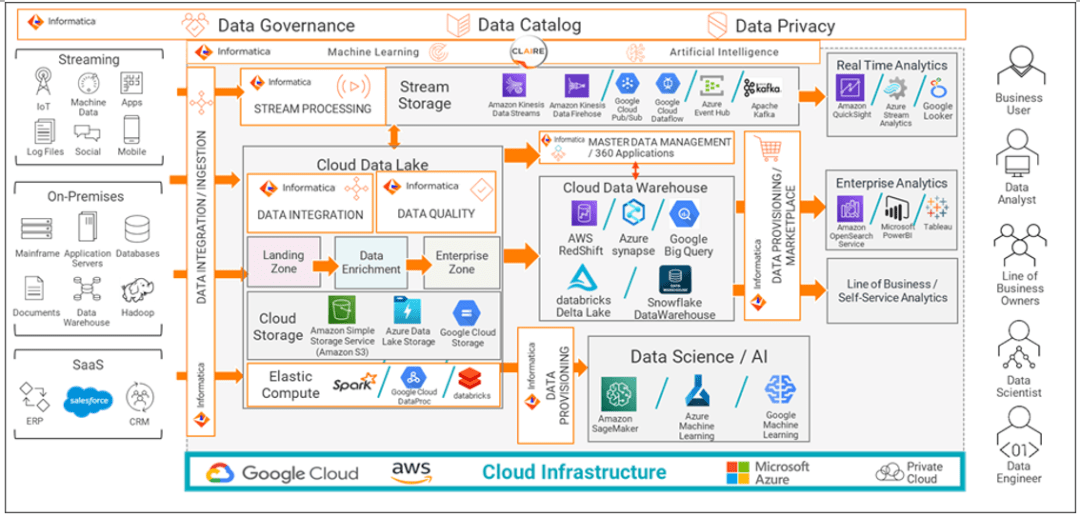
多云和跨云数据管理示例 上图显示了Informatica如何通过多云和跨云数据管理功能帮助您解决碎片和复杂性问题。 2 AI驱动的数据管理自动化 自动化是解决大规模数据碎片化和复杂性的唯一可行选择。然而,超过三分之二(68%)的受调查组织尚未在整个组织内将人工智能用于数据管理。
用于数据管理的人工智能提高了生产率和灵活性 人工智能可以帮助实现数据管理各个方面的自动化,包括数据发现和编目、数据和应用程序集成、清理和掌握、治理、隐私和数据共享。它还提高了所有数据用户的生产率,包括开发人员、架构师、应用程序管理员、数据管理员、财务分析师和一线员工。
用于数据管理自动化的人工智能示例 使用人工智能实现数据管理自动化增加了人工智能在决策和业务流程中的可操作性。优化的数据管理组织可以:
3 数据架构的体系结构 随着组织将更多数据放入更多的云中,他们需要一种方法来连接孤立的数据源,并使整个组织的数据更容易访问。为了解决这些云数据孤岛问题,数据管理领导者正在寻找数据架构的体系结构。 事实上,超过一半(54%)的被调查组织表示,他们正在研究方法和解决方案,或者已经将数据架构的体系结构的某些部分落实到位。
数据架构体系结构有助于优化数据管理 Data Fabric是一个设计概念,它作为一个架构层,用于简化和扩展数据管理任务,并在整个组织中更广泛、更一致地使用数据。
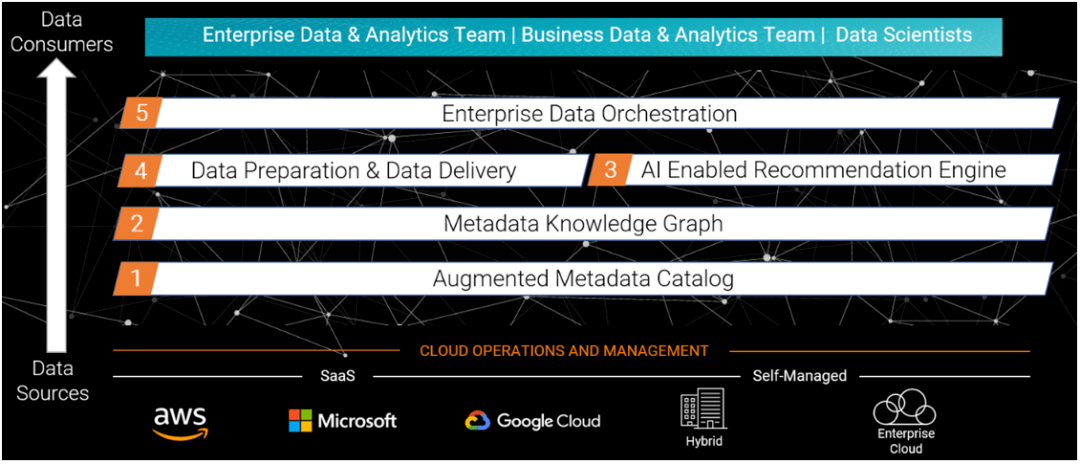
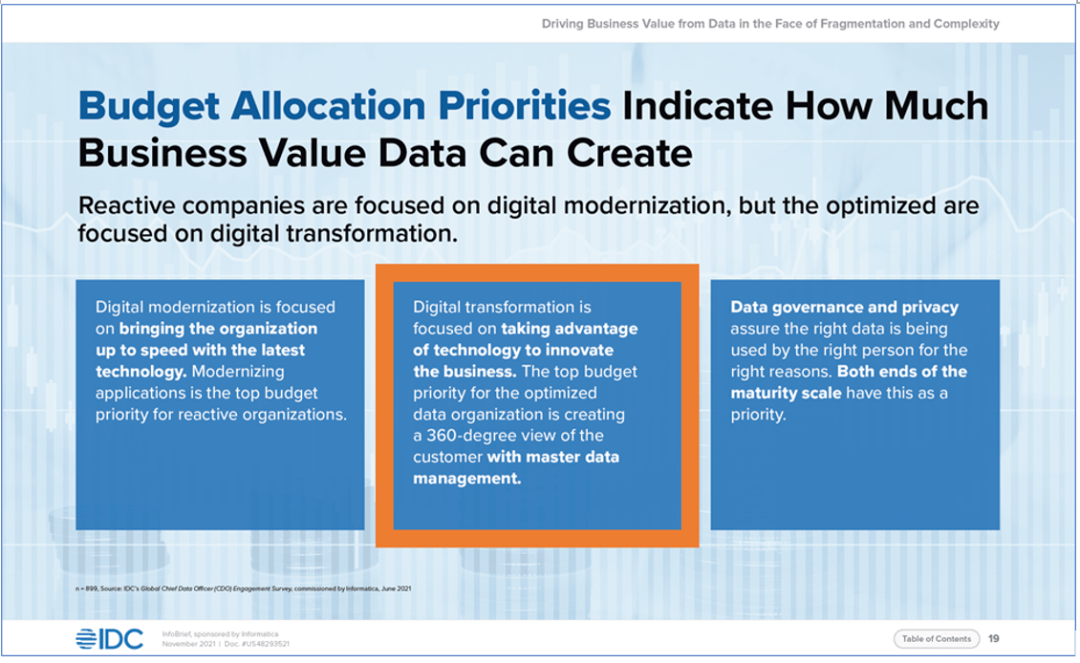
数据架构的关键组件 数据架构的关键组件包括: 1.用于发现和管理数据资产的增强元数据目录 2.用于理解数据资产之间关系的元数据知识图 3.一个支持人工智能的推荐引擎,用于建议使用数据资产 4.支持ETL、流媒体和API数据移动的数据准备和数据交付 5.不同数据管理服务协作的企业数据编排层 嵌入在这五个组件中的是一个AI引擎,它将数据架构执行的数据管理任务进行了自动化。例如,推荐可能感兴趣的数据集,或自动将业务术语和定义与底层技术数据关联,以使业务用户能够自助服务。 4 多域主数据管理(MDM) 随着企业的业务数字化进一步发展,使用云应用程序的数量也在增加。管理端到端的数字体验需要应用程序中提供一致的主数据。 当被问及其数据管理的预算优先事项时,61%的受访者表示,多域主数据管理(MDM)可以360度查看业务,是首要考虑的。
主数据管理是优化数据组织的最优先级预算分配 虽然许多公司最初专注于管理客户数据,但他们很快意识到,需要管理和连接材料、供应商、产品、位置和主数据的其他领域,以获得360度的业务视图,从而帮助他们提供卓越的数字体验。利用多域MDM改善体验的一些方法包括: 客户体验:使营销部门能够通过客户、产品和渠道数据来了解偏好并提供个性化服务。跨客户接触点提供个性化支持和服务。 产品体验:使商务和商品销售团队能够使用客户、产品和位置数据,在整个客户旅程中提供更加吸引的相关产品体验。 供应商经验:使采购和供应商关系团队能够使用供应商、材料和位置数据简化供应商入职流程,并更好地管理整个组织内供应商的总开支。 财务经验:使财务规划和分析团队能够使用客户、产品、渠道、供应商、成本中心和位置数据来建模场景,制定计划,并提供及时的报告和分析。 |




 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫







评论列表